
Replicando datos con PostgreSQL 🐘
Esta semana he estado viendo cómo poder sincronizar datos en PostgreSQL sin necesidad de software de terceros.
Hasta ahora no había tenido la necesidad de hacerlo con PostgreSQL, ya que hasta la fecha estaba usando Microsoft SQL Server y tiene su propio software de replicación.
PostgreSQL no tiene uno parecido al de MS SQL Server, así que lo he implementado de la siguiente manera.
Lo que hago es que cada vez que se inserte una nueva fila en una tabla que quiero sincronizar, se dispara una función que cogerá esa misma fila y la guardará en una tabla de respaldo ubicada en otro servidor.
- Los pasos que seguiré serán:
- Crear la tabla de datos de origen
- Crear el servidor remoto en el servidor origen
- Crear una conexión al servidor remoto desde el servidor origen
- Crear una tabla en la base de datos local que se enlazará a otra en el servidor de respaldo o de destino
- Crear la tabla de datos destino en el servidor remoto
- Crear la función encargada de recibir la nueva fila y hacer la escritura en la tabla de datos replicados
- Crear el disparador que se encargará de llamar a la función anterior cuando se añadan nuevos datos en la tabla de datos de origen.
- Ejecutar pruebas
Replicar datos en bases de datos de PostgreSQL en servidores separados
Para replicar una tabla usaré el mecanismo de Foreign Data Wrapper (FDW) que nos permite acceder a datos de una tabla almacenados en un servidor externo como si estuvieran en una tabla en la base de datos local.
¿Por qué uso FDW y no replico la base de datos completa?
Podría replicar toda la base de datos.
La replicación nos permite crear copias exactas de una base de datos en uno o varios servidores secundarios, que se mantienen actualizadas en tiempo real a medida que se realizan cambios en la base de datos principal.
Para replicar una base de datos en PostgreSQL, se utiliza la herramienta pg_basebackup para crear una copia inicial de la base de datos principal en el servidor secundario, y luego se utiliza la configuración de replicación para mantener actualizada la copia en el servidor secundario a medida que se realizan cambios en la base de datos principal.
Una vez que se ha replicado la base de datos en el servidor secundario, se puede acceder a las tablas remotas como si fueran tablas locales en el servidor secundario.
Esto puede ser más rápido y eficiente que utilizar FDW, ya que no requiere la transferencia de datos a través de la red para cada consulta.
No obstante, la replicación también tiene sus desventajas, ya que puede consumir una cantidad significativa de recursos en el servidor principal y secundario, y requiere una configuración y monitoreo cuidadosos para garantizar la integridad y consistencia de los datos replicados.
Como en este ejemplo sólo quiero mantener replicados datos de una sola tabla utilizaré el mecanismo de Foreign Data Wrapper (FDW).
Un FDW permite acceder a datos almacenados en un servidor externo como si estuvieran en una tabla local en la base de datos actual.
Para hacer referencia a una tabla remota a través de un FDW, tendrás qué:
- Cargar la extensión postgres_fdw
- Crear el servidor remoto
- Crear una conexión al servidor remoto
- Crear una tabla remota en la base de datos local
Una vez creada la tabla remota, podrás acceder a ella como si fuera una tabla local utilizando consultas SQL regulares.
🚩 Antes de comenzar, asegúrate que las versiones de PostgreSQL en cada servidor sean compatibles para hacer la conexión.
Arquitectura que usaremos
En el servidor local replicaremos una tabla que se llamara tabla_origen y cada vez que se inserte un nuevo dato se disparará un trigger que se llamará trigger_replica_en_remoto.
El trigger ejecutará una función llamada funcion_replica_para_servidor_remoto que se encargará en encribir en una tabla local llamada tabla_destino_para_servidor_remoto enlazada con el servidor remoto mediante un foreign server llamado server_13_2.
En el servidor remoto sólo tendremos una tabla llamada tabla_destino_en_servidor_remoto con la misma estructura que la tabla tabla_origen.


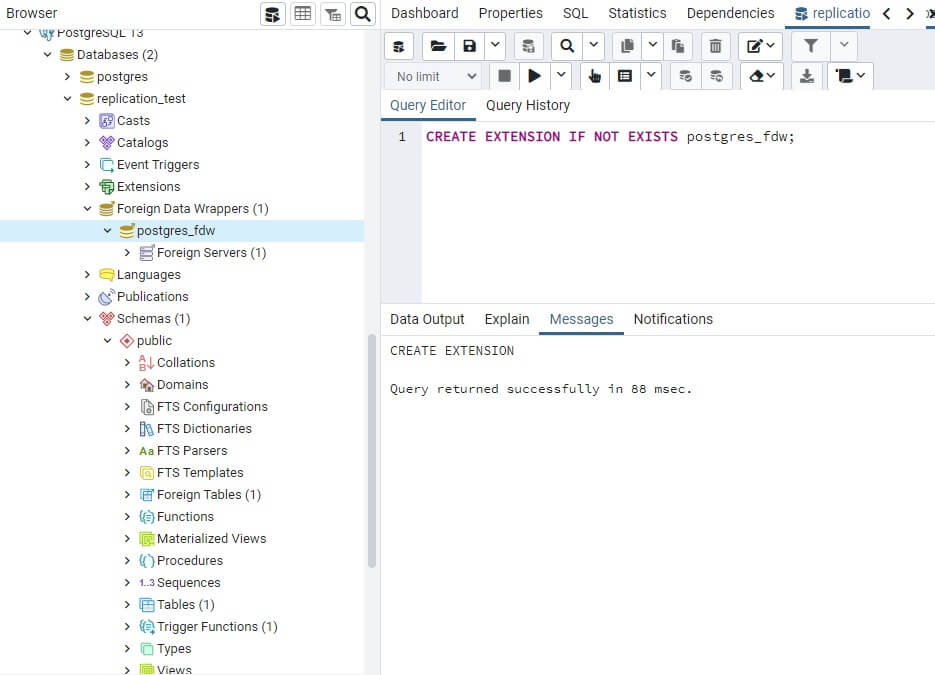
Cargar la extensión postgres_fdw
Para habilitar el conector de datos externos, en ambos servidores principal y de respaldo, ejecutar:
CREATE EXTENSION IF NOT EXISTS postgres_fdw;
Crear servidor remoto de respaldo en servidor local
Crearemos una especie de servidor PostgreSQL virtual en nuestro servidor local
CREATE SERVER server_13_2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host 'ip_servidor', port 'puerto', dbname 'nombre_base_de_datos');

Creando usuario para la conexión con servidor remoto de respaldo
CREATE USER MAPPING FOR usuario_con_el_que_te_quieres_conectar SERVER server_13_2 OPTIONS (user 'user', password 'password');

Crear tabla destino en servidor remoto
En el servidor remoto o de respaldo creo la tabla que recibirá los datos del servidor principal o de origen.
//TABLA DESTINO EN SERVIDOR REMOTO CREATE TABLE public.tabla_destino_en_servidor_remoto ( id integer, description character varying )
🚩 ten en cuenta que el usuario de PostgreSQL que vaya a escribir desde el servidor origen tenga permisos para escribir aquí, en la tabla destino del servidor remoto.
Crear tabla para servidor remoto
Creo la tabla en el servidor principal o de origen que enlazará los datos con el servidor de respaldo o de destino.
CREATE FOREIGN TABLE tabla_destino_para_servidor_remoto (id integer, description character varying) SERVER server_13_2 OPTIONS (schema_name 'public', table_name 'tabla_destino_en_servidor_remoto');

Crear la función encargada de escribir los nuevos datos en la tabla para servidor remoto
Creamos una función a la que llamaremos funcion_replica_para_servidor_remoto.
Entre las palabras reservadas BEGIN y END se escribirá el código de lo que se se quiera ejecutar, en nuestro caso haremos un INSERT a la tabla tabla_destino_para_servidor_remoto (creada en el punto anterior) de los nuevos valores que vienen en la variable NEW
CREATE FUNCTION funcion_replica_para_servidor_remoto() RETURNS trigger AS $$ BEGIN INSERT INTO tabla_destino_para_servidor_remoto VALUES (NEW.*); RETURN NEW; END $$ LANGUAGE plpgsql;

Crear el trigger que llamará a la función de replicar los datos
Crearemos un trigger o disparador que se llamará trigger_replica_en_remoto que se disparará cada vez que se inserte un dato en la tabla tabla_origen y será el encargado de ejecutar la función programada en el punto anterior funcion_replica_para_servidor_remoto
CREATE TRIGGER trigger_replica_en_remoto
AFTER INSERT
ON tabla_origen
FOR EACH ROW
EXECUTE FUNCTION funcion_replica_para_servidor_remoto();

Pruebas
Para probar que todo está correcto añade datos a la tabla_origen, yo añadiré una fila con el id = 3 y el description = test para remoto 3
INSERT INTO tabla_origen (id, description) VALUES (3, 'test para remoto 3');

Ahora compruebo que los datos se hayan replicado en el servidor remoto o de respaldo.

BOOM! 💣, disfrútalo.
Errores y soluciones
Error de permiso para escribir en la tabla foránea
Un escenario en el que tuve problemas fue con una aplicación de Java que escribía en PostgreSQL, pero a la hora de activar la sincronización como te la he explicado no hacía los INSERT, el error que me arrojaba era:
[ERROR] com.inerco.tse.bd.BdAcceso -> insertaRegistros() -> Error al insertar
### Error updating database. Cause: org.postgresql.util.PSQLException: ERROR: permiso denegado a la tabla foránea tb_gas_server80 Where: sentencia SQL: «INSERT INTO tb_gas_server80 VALUES (NEW.*)» función PL/pgSQL replica_tb_gas_para_server80() en la línea 3 en sentencia SQL
El tema era que cuando yo hacía el INSERT desde el PgAdmin, sí lo hacía bien, y era porque yo hacía en INSERT logueado con el usuario postgres en PgAmin.
Cuando me logueé en PgAdmin con el usuario que intentaba acceder el programa de Java ya conseguí que me saliera el error desde PgAdmin.
Si quieres saber cómo loguearte en PgAmin con un usuario distinto ve aquí
Para solventar este problema lo que hice fue asignar al usuario con el que accedía el programa de Java como propietario de las tablas implicadas en la réplica, tanto en el servidor origen como en el remoto.
ALTER TABLE nombre_tabla OWNER TO nuevo_propietario;
Error de mapeo de usuario
Te puedes encontrar con el siguiente error:
ERROR: no se encontró un mapeo para el usuario «usuario_en_cuestion» CONTEXT: sentencia SQL: «INSERT INTO tb_gas_server80 VALUES (NEW.*)» función PL/pgSQL replica_gas() en la línea 3 en sentencia SQL SQL state: 42704
Para solventarlo, añade al usuario para que tenga acceso al servidor.
CREATE USER MAPPING FOR usuario_en_cuestion SERVER server_13_2 OPTIONS (user 'user', password 'password');
¿Sincronizar datos en una misma base de datos de PostgreSQL?
Visto lo anterior, hacerlo en local será mucho más fácil.
Crear las tablas de origen y de replicación
Creamos las tablas, las llamaremos tabla_origen y tabla_replicada. Cada una de las tablas con un campo id numérico y un campo description de texto.
//TABLA ORIGEN CREATE TABLE public.tabla_origen ( id integer, description character varying ) //TABLA PARA DATOS REPLICADOS CREATE TABLE public.tabla_replicada ( id integer, description character varying )

Crear la función encargada de escribir los nuevos datos en la tabla de replicación
Creamos una función a la que llamaremos funcion_replica_origen.
Entre las palabras reservadas BEGIN y END se escribirá el código de lo que se quiera ejecutar. En nuestro caso haremos un INSERT a la tabla tabla_replicada de los nuevos valores que vienen en la variable NEW
CREATE FUNCTION funcion_replica_origen() RETURNS trigger AS $$ BEGIN INSERT INTO tabla_replicada VALUES (NEW.*); RETURN NEW; END $$ LANGUAGE plpgsql;

Crear el trigger que llamará a la función de replicar los datos
Crearemos un trigger o disparador que se llamará trigger_replica_origen que se disparará cada vez que se inserte un dato en la tabla tabla_origen y será el encargado de ejecutar la función programada en el punto anterior funcion_replica_origen
CREATE TRIGGER trigger_replica_origen AFTER INSERT ON tabla_origen FOR EACH ROW EXECUTE FUNCTION funcion_replica_origen();

Pruebas dentro de la misma base de datos
Para probar que todo está correcto añade datos a la tabla_origen
INSERT INTO tabla_origen (id, description) VALUES (1, 'test1');

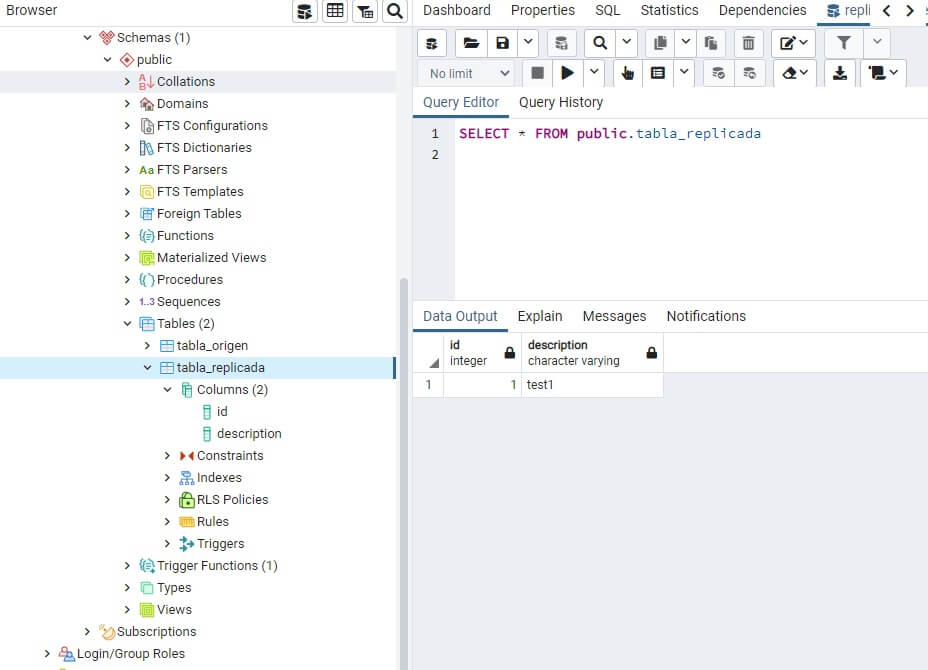
Revisa que se han añadido los datos tanto a tabla_origen como a tabla_replicada
SELECT * FROM public.tabla_origen SELECT * FROM public.tabla_replicada
¿Cómo sé qué versión de PostgreSQL estoy usando?
Para saber qué versión de PostgreSQL tienes ejecuta la instrucción SQL en tu servidor:
SELECT version();
¿Cómo iniciar sesión en PgAdmin con otro usuario?
Para loguearte en PgAdmin con un usuario distinto:
- Desconéctate del servidor
- Con el servidor desconectado haz clic con el botón derecho y pulsa en propiedades
- En la pestaña de Connection cambia el Username con el que quiere entrar

Hasta luego 🖖



